대용량 데이터 처리, 어떻게 하는 걸까?
안녕하세요:)
오늘은 대용량 데이터를 어떻게 처리하는지에 대해 알아보려고 합니다. 유튜브나 구글 같은 대형 플랫폼에서는 매일 수십억 명의 사용자가 콘텐츠를 소비하고, 이로 인해 엄청난 양의 데이터가 실시간으로 처리됩니다. 이러한 대규모 데이터를 처리하고 저장하는 기술이 없다면, 서비스는 속도가 느려지고나 심한 경우 중단될 수도 있습니다.
대용량 데이터를 어떻게 효율적으로 관리하면서 처리할 수 있을까요?? '분산 스토리지 시스템'을 통해 알아보도록 하겠습니다.
분산 스토리지 시스템

Distributed Storage System(DSS)이란, 데이터를 한 곳이 아니라 여러 곳에 나누어 저장하는 시스템입니다. 한 서버(컴퓨터)에 모든 데이터를 저장하는 대신, 여러 서버에 데이터를 나누어 저장함으로써, 더 많은 데이터를 효율적으로 관리할 수 있습니다.
'도서관'으로 예시를 들어보겠습니다.
- 중앙 도서관 하나에 모든 책들을 가져다 놓으면, 사람들이 한꺼번에 책을 빌리러 가게 되고 그렇게 되면 도서관이 매우 혼잡해질 것입니다.
- 그리고 중앙 도서관이 문을 닫게 되면 모든 사람이 책을 빌릴 수 없게 됩니다.
- 하지만, 여러 도서관에 책을 분산해서 배치하면, 사람들이 가까운 도서관에 가서 책을 빌릴 수 있게 되겠죠?
- 그리도 한 도서관이 문을 닫아도 다른 도서관에서 책을 빌릴 수 있기 때문에 책을 빌릴 수 없는 경우가 없어집니다.
위 예시와 같이 '분산 스토리지 시스템'도 비슷한 원리로 동작합니다. 데이터를 여러 서버에 나누어 저장하면,
- 저장 공간을 확장할 수 있고
- 처리 속도가 빨라지고
- 데이터를 더 안전하게 관리할 수 있고
- 하나의 서버에 문제가 생겨도 다른 서버에서 복구할 수 있게 됩니다.
왜 분산 스토리지가 필요할까요?
인터넷 서비스가 점점 커지면서 한 서버에 모든 데이터를 때려박아 저장하는 게 불가능해졌습니다. 유튜브 같은 플랫폼에서 매일 수백 시간, 수천개의 동영상이 업로드되는데, 이 모든 데이터를 한 서버에 저장하면 용량이 부족할 뿐더라 서비스 성능에도 문제가 생길 것입니다.
그래서 데이터를 여러 서버에 나누어 저장하는 분산 스토리지를 사용하게 된 것이죠. 이제 분산 스토리지가 어떻게 동작하는 지 알아볼까요?
분산 스토리지의 분산 처리
분산 스토리지는 데이터를 어떻게 저장하고 처리할까요? 세 가지로 나눠서 보도록 하겠습니다.
- 데이터 분산 저장
- 데이터를 여러 서버에 나누어 저장해서, 특정 서버에 과부하가 걸리지 않도록 합니다. 데이터를 여러 곳에 나누면 서버 한 대에 문제가 생겨도 데이터 손실을 막을 수 있게 됩니다.
- 데이터 복제
- 만약 한 서버에 문제가 생긴다면? 이럴 경우, 복제된 데이터가 다른 서버에 저장되어 있어서 복구할 수 있습니다.
- 백업과 비슷한 개념으로 봐도 좋은데, 예를 들어서, 구글의 분산 스토리지는 중요한 데이터를 3곳 이상에 복제해 두기 때문에, 하나가 고장 나더라도 문제가 없습니다.
- 데이터 동시 처리
- 여러 서버가 동시에 분산 작업을 처리함으로써 사용자에게 빠른 응답을 제공합니다.
분산 스토리지 연계 기술
분산 스토리지에 추가적인 기술을 적용하면 대규모 트래픽도 효과적으로 관리할 수 있게 됩니다.

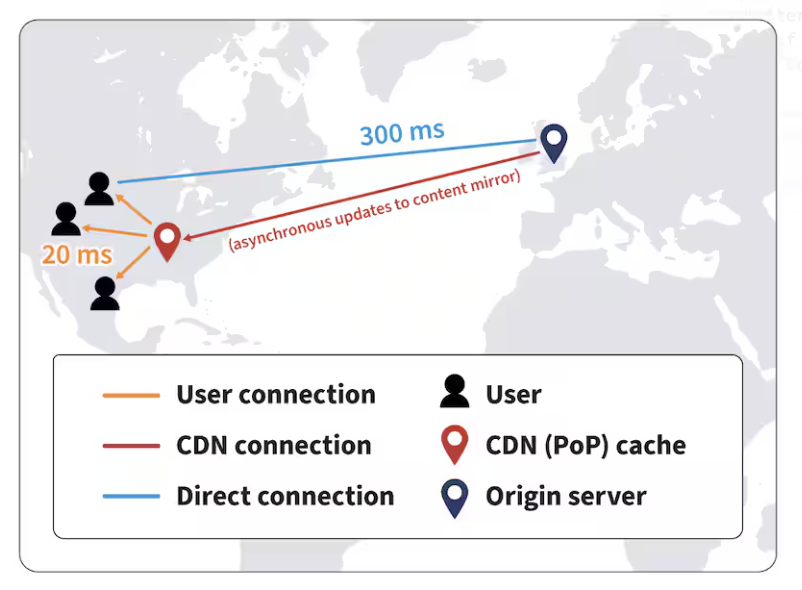
대표적인 기술이 CDN과 GSLB입니다. 간단하게 말씀드리면,
- CDN은 Contents Delivery Network로 사용자와 가까운 서버에 콘텐츠를 분산 저장하여 빠르게 제공하는 기술이고
- GSLB는 Global Server Load Balancing으로 전 세계에 분산된 서버들 간의 트래픽을 효율적으로 분산시키는 기술입니다.
(자세한 건,
https://jinuk-io.tistory.com/entry/2-GSLB%EC%99%80-CDN%EC%9D%84-%ED%99%9C%EC%9A%A9%ED%95%9C-%EC%9B%B9-%EC%84%9C%EB%B9%84%EC%8A%A4-%EC%B5%9C%EC%A0%81%ED%99%94
: 이 링크에 들어가시면 읽어보실 수 있습니당 ㅎㅎ)
두 기술과 분산 스토리지가 더해지면 어떤 작업이 가능해질까요? 적용 사례를 통해 위 내용을 정리하면서 살펴보겠습니다.
분산 스토리지와 CDN, GSLB의 실제 적용 사례

대표적인 사례로 구글의 유튜브가 있습니다. 위의 분산 스토리지 내용에 추가해서 살펴보겠습니다.
- 유튜브에 동영상을 업로드할 때, 그 동영상은 전 세계 여러 서버에 분산 저장됩니다.
- 구글은 GFS(Google File System)라는 분산 스토리지 시스템을 사용합니다. 이거 덕에 전 세계에 있는 서버에 데이터를 나누어 저장할 수 있기에 유튜브 같은 서비스가 매일 방대한 양의 동영상을 처리할 수 있죠.
- 한국에서 동영상을 업로드하면, 해당 영상은 한국뿐만 아니라 전 세계 여러 지역의 서버에도 나누어 저장된다는 것이죠. 이렇게 데이터를 여러 서버에 나누면, 특정 서버에 과부하가 걸리지 않고, 동영상 조회시 더 빠르게 데이터를 제공할 수 있게 됩니다.
- 그리고 동영상 데이터는 단순히 저장되는 것만 아니라 복제가 됩니다.
- 한 서버에만 저장되면 그 서버에 문제가 생겼을 때 데이터를 잃을 위험이 있지만, 유튜브는 데이터를 여러 서버에 복제하여 관리하기 때문에 데이터 손실이나 복구에도 문제가 생기지 않도록 합니다.
- 많은 사람들이 한꺼번에 하나의 동영상을 시청하려고 하면, 여러 서버가 이 요청을 나눠서 처리하게 됩니다.
- 한국에서 사용자가 유튜브에 접속할 때, 한국 내에 있는 서버들이 동시에 작동하여 동영상 스트리밍을 제공하고, 이렇게 분산된 서버들이 데이터를 처리함으로써 빠르고 끊김이 없는 서비스가 제공될 수 있게 합니다.
- 이러한 분산 스토리지 시스템을 더욱 효율적으로 관리하기 위해, 유튜브는 GSLB와 CDN 기술을 함께 사용합니다.
- 한국에 있는 사용자가 유튜브에 접속하면, GSLB는 사용자의 위치와 서버의 상태를 고려하여 가장 가까운 서버나 트래픽이 적은 서버로 사용자의 요청을 분배합니다. 이렇게 하면 서버에 과부하가 걸리는 것을 방지하고, 사용자에게 더 빠른 서비스를 제공할 수 있습니다.
- 한국에서 동영상을 시청하는 경우, 한국에 위치한 서버에서 해당 동영상을 불러오기 때문에 대기 시간이 줄어들어 더 빠르게 스트리밍할 수 있게 됩니다. 동시에, 사용자가 몰려서 특정 서버에 부하가 걸리더라도, CDN을 통해 다른 서버에서 데이터를 가져와 서비스의 끊김 없이 안정적인 스트리밍이 가능합니다.
이처럼 유튜브와 같은 대규모 서비스는 분산 스토리지 시스템을 활용해 전 세계 사용자에게 안정적이고 빠른 콘텐츠 제공을 실현하고 있습니다.
끝내는 말
오늘은 분산 스토리지 시스템을 통해 대용량 데이터를 효율적으로 처리하는 방법과 추가적으로 CDN, GSLB가 실제로 어떻게 적용되고 사용되고 있는가를 알아보았습니다. 유튜브와 같은 대형 플랫폼이 전 세계 사용자에게 안정적이고 빠른 서비스를 제공할 수 있는 비결이 바로 이러한 기술들에 있음을 살펴보았는데요.
평소에 유튜브를 자주 보지만 한 번도 생각해보지 않았던 내용인데, 오늘 누가 '???: 유튜브는 그 많은 동영상을 어떻게 저장할까?' 라는 질문을 제 옆에서 했던 게 생각나서 생각난 김에 작성해보았습니다. 그러다 보니 유튜브를 예시로 들게 되었네요 ㅎ.ㅎ
읽어주셔서 감사합니다:)